Stop Measuring Data Quality. Start Engineering It.
Your Data Quality Score Isn't the Problem. It's the Symptom.
Organizations spend millions on data quality tools and still face failures. DQ tools measure defects after the damage is done. iceDQ engineers reliability into every pipeline stage: pre-production testing, source-to-target validation, and production monitoring. One rule set from Dev to Production. No rebuilding. No blind spots. No bad data reaching the business.
Trusted by Fortune 500 companies













Why Choose iceDQ?
Data Reliability Engineering designed to replace reactive data quality scoring with proactive validation, reconciliation, and monitoring.
Pre-Production Data Validation
Test every data pipeline in Dev, QA, and UAT before go-live. iceDQ catches transformation errors, schema mismatches, and business rule violations before bad data reaches production - not after.

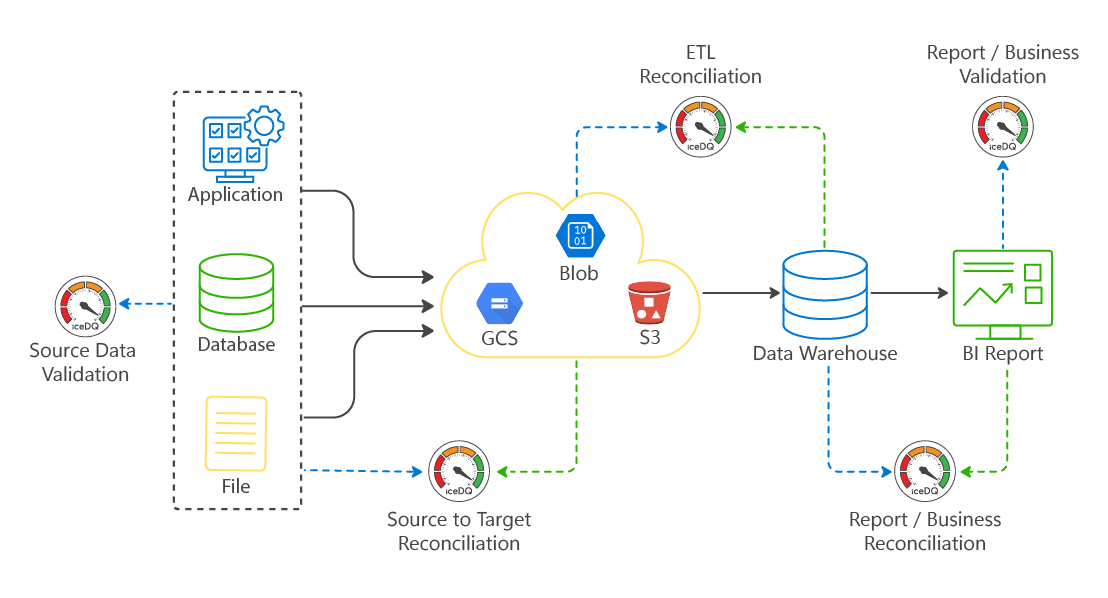
Full Source-to-Target Reconciliation
iceDQ validates 100% of records across every pipeline hop - from raw source data through every transformation layer to the final target. Row counts, attribute values, business rules, and referential integrity - all reconciled, not sampled.

Deploy Testing Rules into Production Monitoring
The validation rules you build in pre-production do not get left behind. Deploy them directly into production as continuous monitoring jobs - so the same logic that certified your pipeline becomes your production safety net.
CI/CD and DataOps Integration
Embed data reliability engineering into your CI/CD pipeline using API-first design. Automated validation runs on every deployment - catching regressions before they reach production, with results pushed to JIRA, Azure Test Plans, and ServiceNow.

Auto-Rule Generation Across Every Layer
iceDQ's AI-driven auto-rule generation scans source and target schemas and generates validation and reconciliation rules across thousands of tables in hours - covering completeness, data types, transformation logic, duplicates, and business rules.

One Platform. Testing, Monitoring, and Observability.
Replace multiple siloed tools - your DQ scorer, your pipeline tester, your monitoring tool - with one unified platform. iceDQ covers the full data reliability lifecycle: Build and Test, Run and Monitor, Produce and Observe.
Data Quality vs. Data Reliability
Your data quality tool measures outcomes. iceDQ engineers them - before, during, and after production.
| Aspect | Data Quality Tool Approach | iceDQ - Data Reliability Approach |
|---|---|---|
| When it runs | After data reaches production | Before, during, and after - from Dev to Production |
| What it checks | Scores DQ dimensions at the consumption point - accuracy, completeness, timeliness | Validates 100% of records at every pipeline stage - source data, transformations, targets |
| How it works | Reactive - detects defects after the damage is done | Proactive - prevents defects at the source before they propagate |
| Data coverage | Samples 5-10% of records - the other 90% is untested | Validates billions of records with no sampling - every record, every time |
| Validation and reconciliation | Limited - flags individual record issues but cannot reconcile source to target | Full source-to-target reconciliation at every hop - row counts, attributes, transformations, and business rules |
| Pre-production testing | Not designed for it - built to observe final data, not test pipelines | Built for it - automates data pipeline testing in Dev, QA, and UAT before go-live |
| Production monitoring | Post-production scoring only - no embedded pipeline checks or real-time controls | Deploy the same validation rules built in testing directly into production as continuous monitoring jobs |
| Rule reuse | Rules live in the DQ tool only - rebuilt separately for each environment | One rule set reused across Dev, QA, UAT, and Production - no rebuilding required |
| Scope | Final production data only | Entire data ecosystem - source files, raw data, pipelines, transformations, and production |
| Approach | Reactive inspection - measuring defects that already exist | Proactive engineering - building quality in from the start |
Out-of-Box Checks
Accelerate Data Reliability Engineering with Prebuilt Validation and Reconciliation Checks











Features

Easy, Low-Code/No-Code Testing
- Automate data validation and reconciliation with minimal effort
- Powerful scripting for complex validation scenarios, with rule-based validation and reconciliation

High-Performance, Scalable Testing
- Achieve million-record-per-second validation speeds
- Flexible deployment on-prem or in the cloud with parallel and cluster processing

Seamless Connectivity and Integration
- Connect to over 150 databases, cloud systems, and file sources
- Integrate seamlessly with test case management and ticketing systems

Accelerate DataOps with API-First Design
- Fully compatible with CI/CD pipelines
- Automate regression testing and enable end-to-end data reliability for DataOps
Benefits
See the transformation iceDQ delivers across real data reliability projects



 ️
️


Trusted by Industry Leaders
Every morning our DQ dashboard said we were fine. Turns out 30% of our ETL transformations were broken. iceDQ caught it on day one in pre-production. Day one.

Morgan Stanley
Three years with a DQ tool. Three years of failed audits. Then iceDQ tested every record, every transformation, source to target. We haven't had a single audit finding since.

Arch Insurance
I used to dread 2am calls about bad data. The day we deployed iceDQ's testing rules into production monitoring? Those calls stopped. Same rules, now our safety net.

Pfizer
Our old tool said 94% complete. Great, right? Except that missing 6% was customer IDs across 18 million records. iceDQ's reconciliation caught it before it wrecked our CRM.

wiley
5,000 hours. Half a million dollars. That's what iceDQ saved us on one migration project. I didn't believe the numbers at first either, but they held up.

PepsiCo
100% test coverage used to be a slide in a presentation. After iceDQ, it's actually real. Our entire team still talks about how fast the implementation went.

BMC Software
Built-In Functionalities
 Parameterization
Parameterization Rules Wizard
Rules Wizard Data Reliability Engineering
Data Reliability Engineering Data Monitoring
Data Monitoring Built-In Scheduler
Built-In Scheduler ️User-Defined Function
️User-Defined Function Flat File Testing
Flat File Testing ️SAP HANA Migration Testing
️SAP HANA Migration Testing Reporting and Analytics
Reporting and Analytics Security - LDAP and SSO
Security - LDAP and SSO Query Designer
Query Designer Regression Testing
Regression Testing Salesforce Migration TestingAlerts and Notifications
Salesforce Migration TestingAlerts and Notifications ️Integrated Key Vault
️Integrated Key Vault