


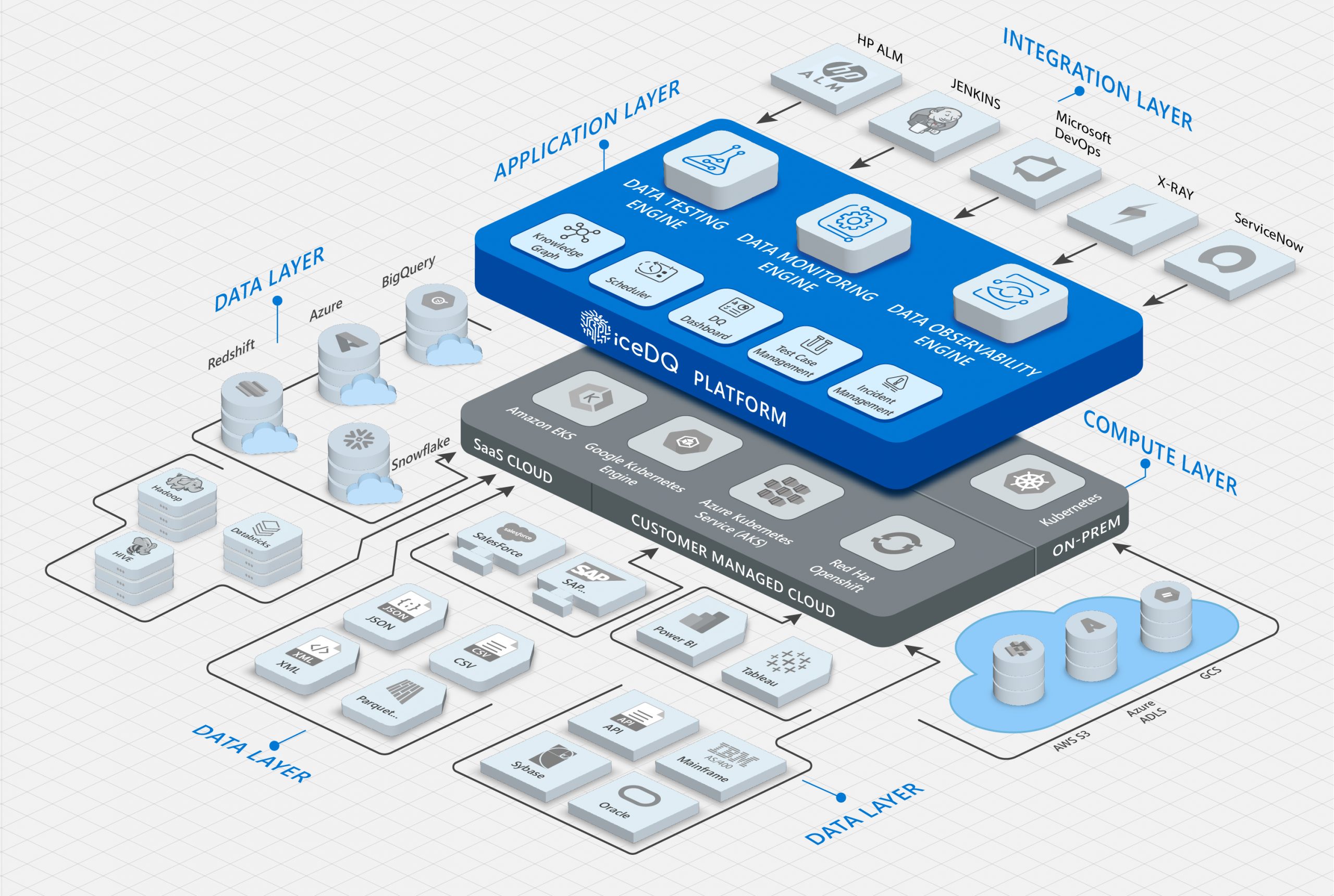
iceDQ Platform Overview
End-to-end data reliability platform for enterprises
End-to-end data reliability platform for enterprises
iceDQ is a purpose-built platform with integrated data testing, data monitoring and AI based data observability capabilities.
iceDQ is the only platform that works across the entire data development lifecycle – development, QA, and production – ensuring robust data processes and reliable data.

 Data Testing
Data Testing
 Data Monitoring
Data Monitoring
 Data Observability
Data Observability
 Scheduler
Scheduler
 Connectors
Connectors
 Integrations
Integrations
 Dashboard & Reporting
Dashboard & Reporting







 |
GRC - Governance, Risk and Compliance | Improved risk management with accurate data identification, effective data controls, and enhanced incident response. Achieve stronger regulatory compliance, accurate reporting and reduced compliance costs. | |
 |
Revenue | Improve your top and bottom-line revenue by improving customer experience, providing the right data to decision makers, speeding up data centric projects and collaboration across data teams and business. | |
 |
Productivity | When data is accurate and complete, there are fewer errors and rework in processes, leading to cost savings. Time spent correcting bad data can be redirected to more productive activities. |

Automatically generates metrics with AI and machine learning to observe and report anomalies in production data.

Engineered with API-first approach to seamlessly integrate in CI/CD pipeline such as Jenkins, Azure Pipelines, Bamboo and GIT repository.

iceDQ does not use database for processing instead it uses Java processing for high performance and low latency. It also has Spark for scaling to petabytes of data.

Explore additional capabilities such as SSO, Key Vault, Query Designer, UDF, reporting, ticketing, and more.


No. We have our proprietary high-performance in-memory engine and a scalable big-data engine. This helps lower your database load and costs.
Companies can opt for the SaaS option on AWS or the self-managed on-premises options.
No. The customer controls data access for both the SaaS and on-premises option.
It’s a consumption-based license per user per server or enterprise.
