iCEDQ Big Data Edition

Organizations who have a big data ecosystem and want to scale testing of billions of rows can use our iCEDQ Big Data Edition. The iCEDQ Big Data Edition uses Java, Groovy, and Apache Spark to process the data for testing. Currently, iCEDQ supports Cloudera/ Hortonworks platform for running Spark Engine. We are in the process of adding following platforms too AWS EMR, Databricks, Azure HD Insight, GCP Cloud Dataflow.
iCEDQ Big Data Edition supports six different types of Rules.
- Cluster Validation
- Cluster Recon
- Validation Rule
- Recon Rule
- Checksum Rule
- Script Rule

How does Big Data Edition work?
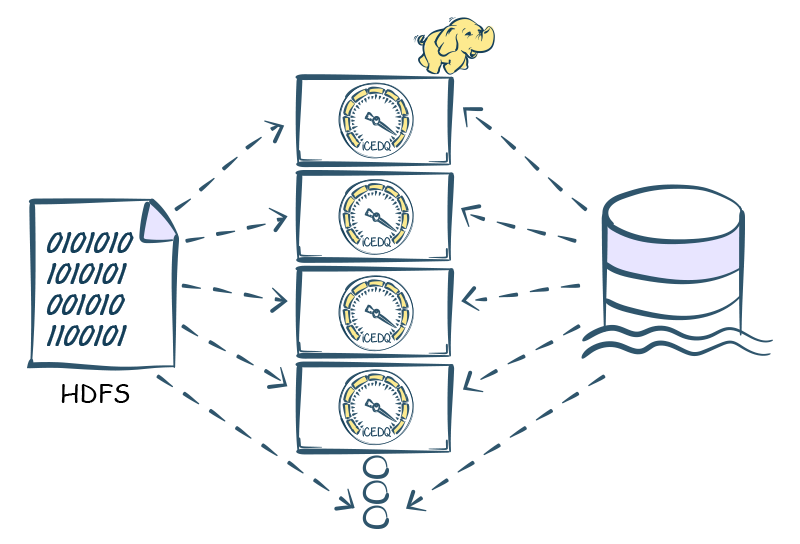
Every Rule or Regression Pack is evaluated using Apache Spark cluster. User can scale the performance by scaling the Spark cluster.
In the Big Data Edition, the Rules engine uses JDBC or native connectors to read data from different sources. Unlike Standard and HT Rules engine, the Spark Rule engine reads all the data into the cluster and sorts it parallelly. It then identifies missing and matching records and evaluate expressions in parallel. The Spark Engine writes all the data issues to an exception report in HDFS.
Big Data Edition gives 100x better performance than Standard edition for High Volume Datasets.
Features

Built-in Scheduler
Now schedule all your tests in advance, iCEDQ Big Data Edition supports daily, weekly and monthly job scheduling. You can run jobs offline also.

Regression Testing Suite
iCEDQ Big Data Edition supports creation of regression testing packs by combining multiple rules. You can also store batches for future use.

Alerts and Notifications
It connects with users via email notifications and notifies them about success or failure of a job. It also notifies for scheduling tool alerts.

Advanced User Level Security
Apart from system level access, database user level security and LDAP security are also available. You can also limit access to data for specific users.

CI/CD pipeline integration
You can implement DevOps for your data centric project with iCEDQ Big Data Edition. It supports Jenkins plugin and has an API for Jira, Bamboo and Git, which results in faster application delivery, enhanced innovation and gives a stable operating environment.

Custom Reporting and Dashboard
It has an embedded custom reporting and dashboarding solution, where you can create custom dashboards, create custom reports, share reports and dashboards. It has HTML-5 Reporting utility, Dashboard utility and is independent of any external tool for this functionality.

Speed
It can reach up to 14.1M rows/sec speed while testing data with Recon rule.

Centralized Knowledge Repository
It stores the metadata and rules in database repository which can be PostgreSQL, Oracle or SQL Server. Clients can access the centralized metadata from any PC, build custom reports, store and archive execution log for compliance or use APIs to share with other applications.
New Connectors
The Spark engine and the connectors are separate which allows easy addition of new connectors.